
XPath is a language used to navigate and select elements from an XML document. It is commonly used in web development and testing, particularly with Selenium’s open-source testing tool. XPath allows Selenium to locate and interact with elements on a web page, making it an essential tool for automating web applications.
- What is XPath in Selenium
- Terminologies used in XPath
- How to select nodes
- Types of XPath
- How to write XPath in Selenium
- XPath Axes in Selenium
What is XPath in Selenium
XPath, or XML path language, is a query language that selects nodes from an XML. It is one of the most commonly used methods to locate the elements in Selenium.
The XPath language is based on a tree representation of a webpage. It provides the ability to move through the tree and select various nodes using various criteria.
Selenium Webdriver supports XPath to locate elements using XPath expressions, also known as XPath Query.
Note: We know that selenium has multiple locators to locate an element within a webpage. Now, the closest one to an XPath is a CSS selector, but one advantage of using XPath over CSS is that by using XPath, we can search forwards or backwards in the DOM hierarchy, while CSS works only in a forward direction.
Terminologies used in XPath
There are several terminologies that one must know before moving to use XPath –
We will use the below HTML document in our examples –
<html>
<head>
</head>
<body>
<p>Codekru Tutorial On XPath</p>
</body>
</html>
Node
DOM represents an HTML document as a tree of nodes, and the topmost element is called the root node.
In our example, <html>, <head>, <body>, <p> and Codekru Tutorial On XPath are nodes in the above HTML document where <html> is the root node.
Atomic values
Atomic values are nodes with no children or parents.
Here, Codekru Tutorial On XPath will be considered as an atomic value.
Parents
We discussed that DOM represents an HTML document as a tree of nodes. So, in that tree structure, every node or attribute has exactly one parent, with the root node on the top with no parent.
The parent node is the immediate predecessor of a node.
If we consider our example, then
- <html> is the parent of <head> and <body>
- <body> is the parent of <p>
Note: Please remember that <html> is not the parent of <p> node. It’s an ancestor.
Children
Every node can have zero or more children. The children node is the immediate successor of a node.
Considering our HTML document –
- <head> and <body> are the children of <html>
- <p> is the children of <html>
Note: Please remember that <p> is not the child of <html> node. It’s a descendant.
Siblings
Nodes that have the same parent are sibling nodes. <head> and <body> are sibling nodes in our HTML code above.
Ancestors
A node’s parent, parent’s parent, and so on. <html> node is the ancestor of <body>, <head> and the <p> node.
Descendants
A node’s children, children’s children, and so on. <p> node is the descendant of <body> and the <html> node.
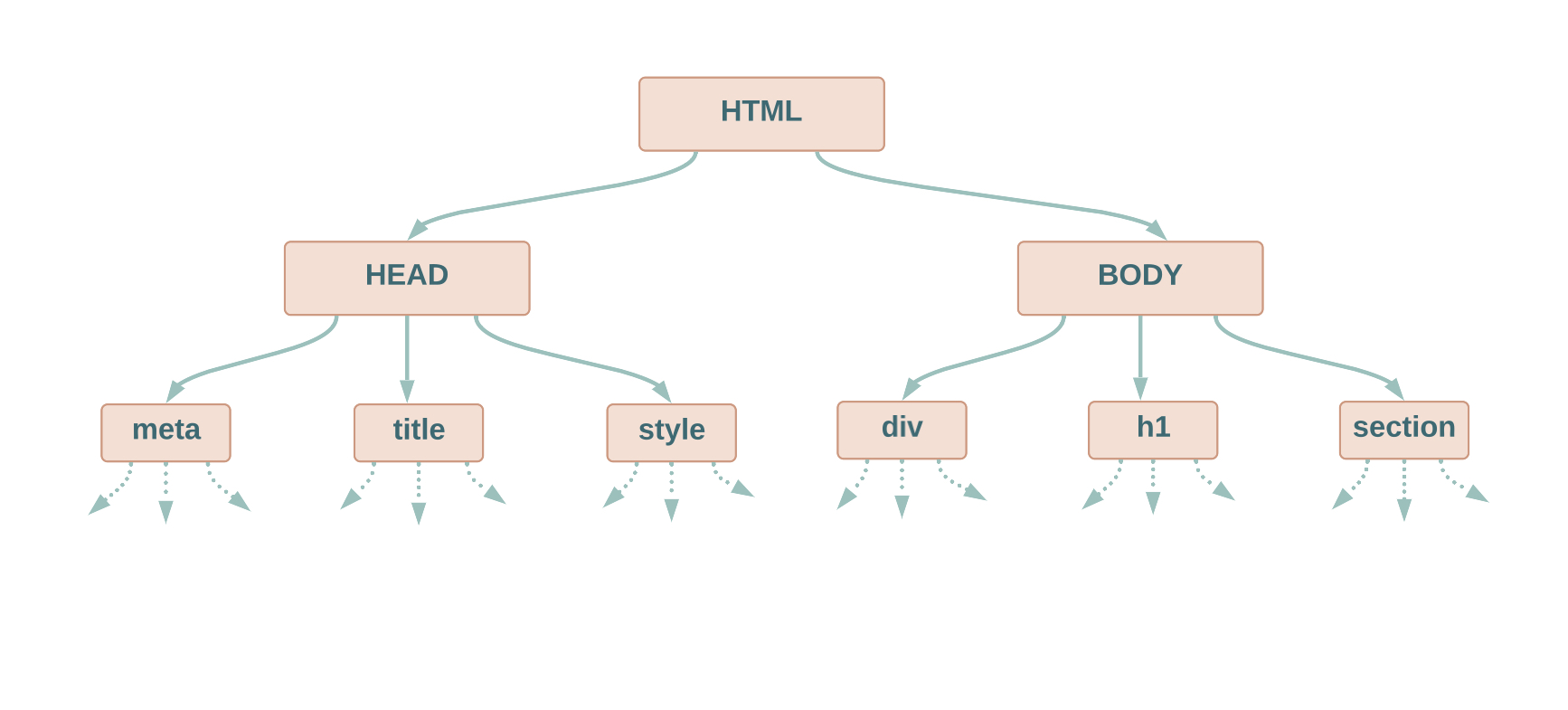
How to select nodes using XPath in Selenium
While writing XPath, knowing how to select a node from the tree is important. This will help better the understanding of XPath and locate elements associated with the nodes.
We will use the HTML document below to understand how to select nodes while writing XPath in selenium.
<html>
<head>
</head>
<body>
<div>
<h1>Codekru Tutorials </h1>
</div>
<div>
<h2>Guide to XPath in Selenium</h2>
</div>
</body>
</html>
XPath uses path expressions to select nodes from the tree. The node is selected by following a path or steps. Below are some useful path expressions –
Let’s look at each of them one by one.
nodename
This will select all nodes with the name “nodename”. Eg. div will select all the div elements in our HTML example above.
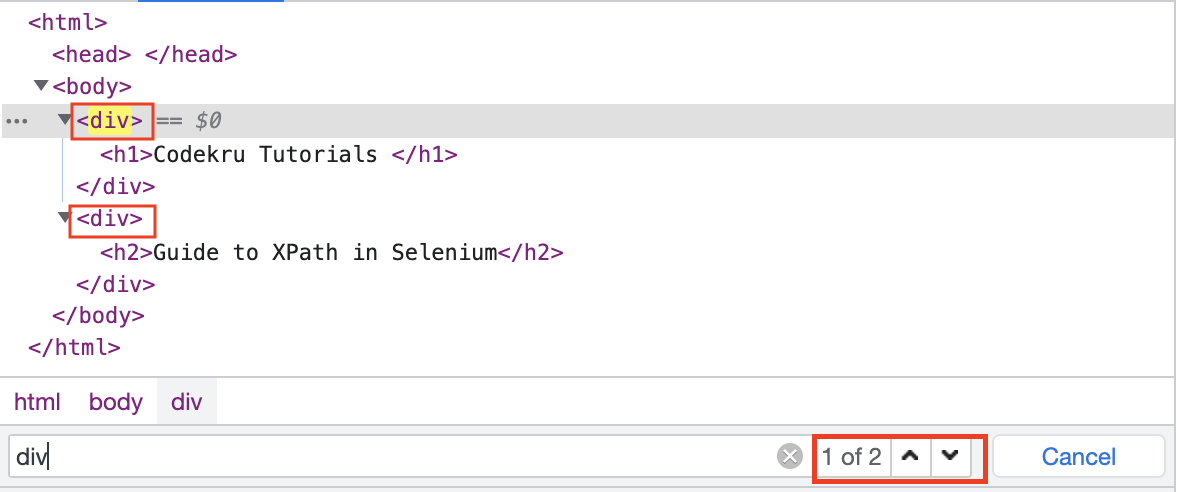
/ (slash)
/ (slash) in XPath will select the elements relative to the root element. So, “/html” will select the root HTML element, and “/html/body/div” will select the div elements inside the body.
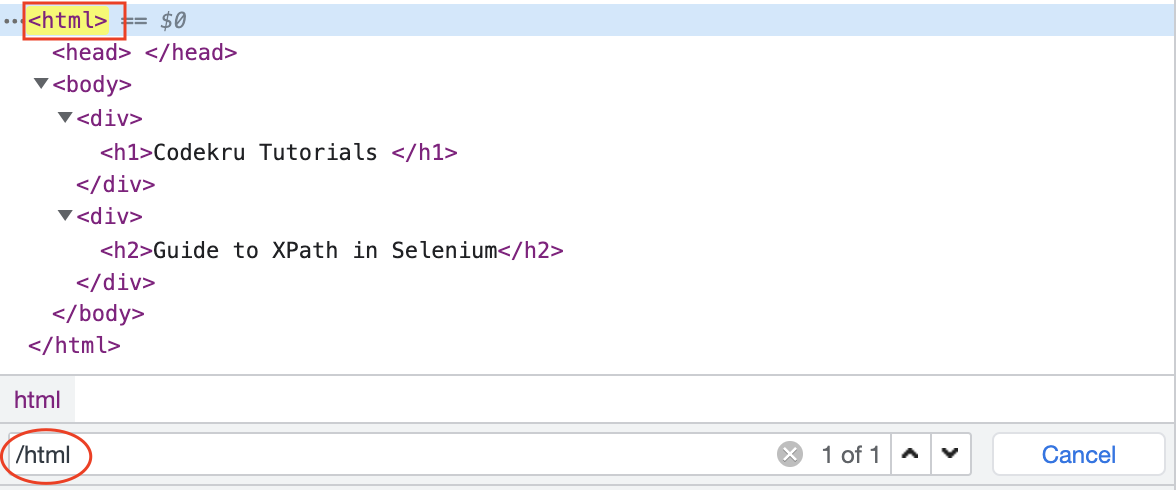

- If a slash is used at the start of an XPath ( like “
/html” ), then it defines an absolute XPath. - And if a slash is used in the middle of an XPath, it defines a parent-child relationship.
- Like “
html/body/div” defines that “html” is the parent of the “body” element, which in turn is a parent of the “div” element.
- Like “
// (double slash)
This will select node(s) that matches the selection from the current node, irrespective of its position in the document.
E.g.,”//div” will select all the div elements no matter where they are in the document.
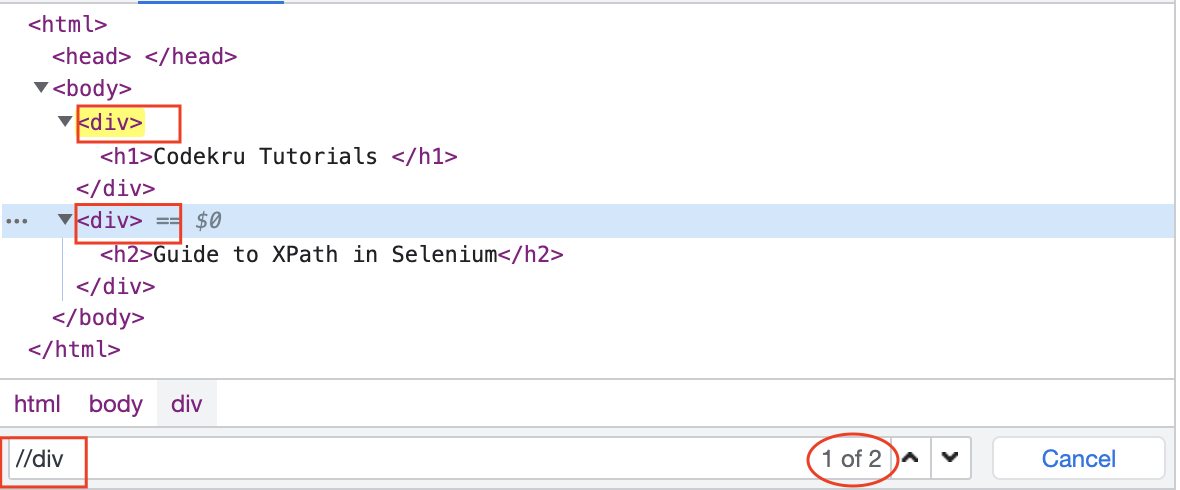
If a double slash is used in the middle of an XPath, it defines a descendent relationship. E.g., //div//h1 will select all h1 elements that are descendants of the div elements.
. (dot)
It represents the current node. E.g., “//div/.” will select the div node in the document.
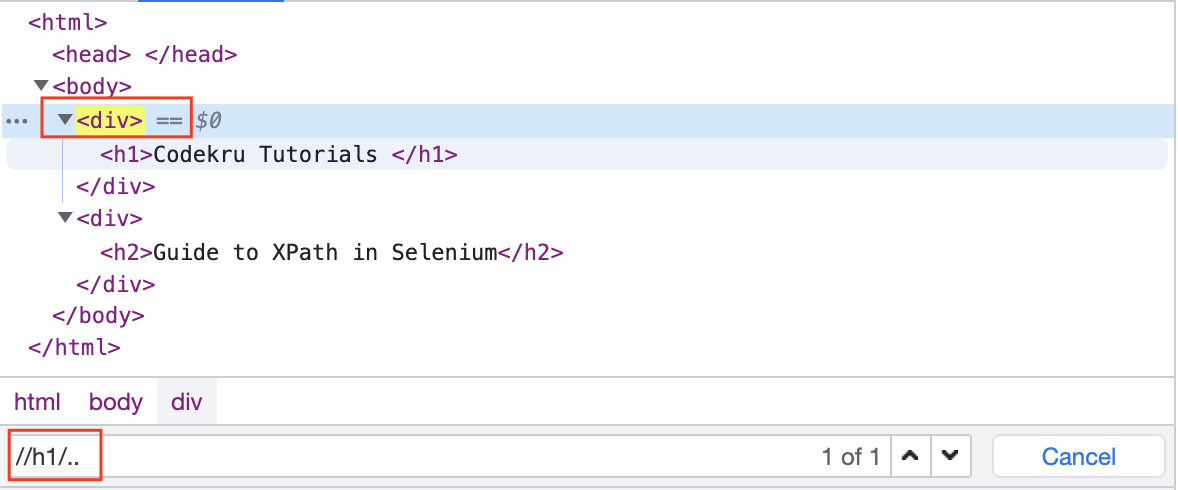
.. (double dot)
This will select the parent node of the current node. In our example, “//h1/..” will select the parent node of the h1 node.
@ (address sign)
@ in XPath represents an attribute.
<a class = "cr1" href = "https://www.codekru.com">Codekru website </a>In the above HTML code, “class” and “href” are the attributes, so using “//@class” and “//@href” will select nodes with the class and href attributes, respectively.
Types of XPath in Selenium
There are two types of XPath in Selenium – Absolute XPath and Relative XPath.
Absolute XPath
The absolute XPath starts from the tree’s root, or we can say that it starts from the first node of the document. Then it traverses to the required node, one node at a time, using a single slash.
Let’s take the example of the HTML below document.
<html>
<head>
</head>
<body>
<div>
<h1>Codekru Tutorials </h1>
</div>
<div>
<a class = "cr1" href = "https://www.codekru.com">Codekru Website link</a>
<h2>Guide to XPath in Selenium</h2>
</div>
</body>
</html>
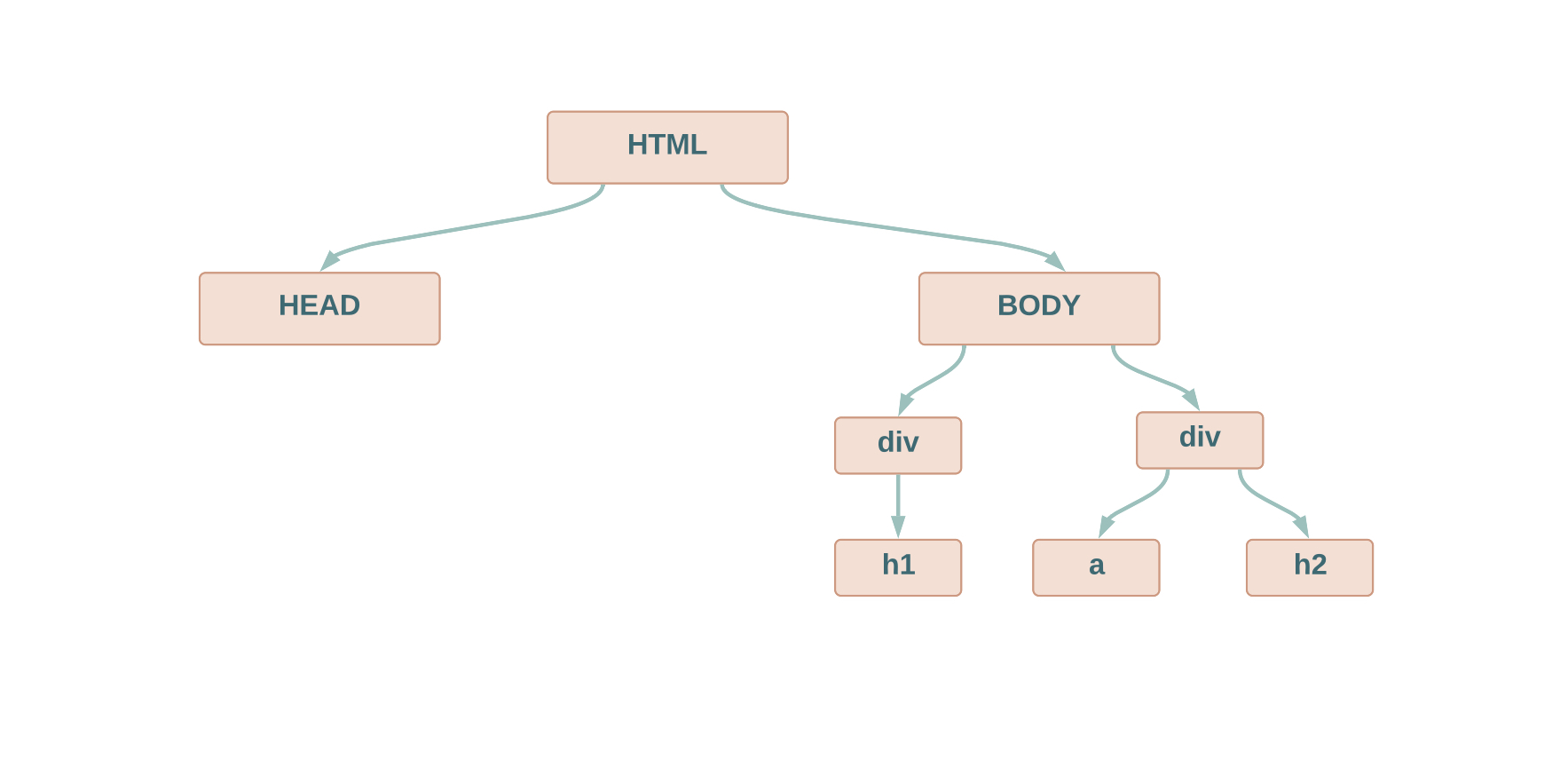
Let’s say we want to reach the <a> node using absolute XPath. Below is the tree structure of the above HTML document, highlighting the tags and the relationship between them.
- Absolute XPath uses a single slash to reach a particular node. A single slash also represents a parent-child relationship when used in the middle of an XPath in Selenium.
- Absolute XPath also starts from the root node.
By keeping the above points in mind, we will start from the “html” node and move to the “a” node using a single slash ( parent-child relationship ).
- So, “
/html” selects the root node - “
/html/body” selects the body node, which is the child of html node. - “
/html/body/div” selects the div nodes, the children of the body node. - and finally “
/html/body/div/a” selects the “a” node.
So, “/html/body/div/a” is the final absolute XPath which selects the “a” node in our HTML document.
A disadvantage of using absolute XPath is that any changes to DOM or attribute will invalidate the absolute XPath, and we would have to write the XPath again.
Relative XPath
The disadvantage of the absolute XPath can be overcome by using the relative XPath in selenium. It can start from any node and then move forward or backwards to select the required node.
Relative XPath normally starts from the double slash ( // ), which can select any node and then use any XPath expressions to select the required node.
Let’s take the same HTML example.
<html>
<head>
</head>
<body>
<div>
<h1>Codekru Tutorials </h1>
</div>
<div>
<a class = "cr1" href = "https://www.codekru.com">Codekru Website link</a>
<h2>Guide to XPath in Selenium</h2>
</div>
</body>
</html>
Now, there are multiple ways to write the relative XPath to select the “a” node –
- “
//a” selects the “a” node. - “
//div” selects the “div” node, and then we can use the single slash to move to the child “a” node. So, “//div/a” selects our “a” node. - “
//body/div/a” also selects the “a” node. - We can also use the double slash in the middle of the XPath to directly reach the descendent by skipping children in between.
- So, “
//body/div/a” can also be written as “//body//a” and they will select the same “a” node.
- So, “
There are many other ways of writing an XPath which we are going to explore in the next section.
How to write XPath in Selenium
We will use the below HTML code in our example to demonstrate writing XPath in Selenium –
<html>
<head>
</head>
<body>
<div>
<p>Codekru Tutorials </p>
</div>
<div>
<a class = "cr1" href = "https://www.codekru.com">Codekru Website link</a>
<p>Guide to XPath in Selenium</p>
</div>
<div>
<a href = "https://www.codekru.com/selenium">Selenium Tutorials Link</a>
</div>
</body>
</html>
We hope that you remember the various XPath expression we discussed earlier. To recap, below are the most commonly used XPath expressions –
We will use most of them in this section to write XPath.
How to write the XPath of elements containing a certain attribute?
We would have to use the “@” to select elements with a certain attribute.
Syntax –
//@attribute_name
In the below code, “href” and “class” are the attributes of the “a” tag.
<a class = "cr1" href = "https://www.codekru.com">Codekru Website link</a>Let’s say we want to select all elements containing the “href” attribute, then below XPath will do that –
//@href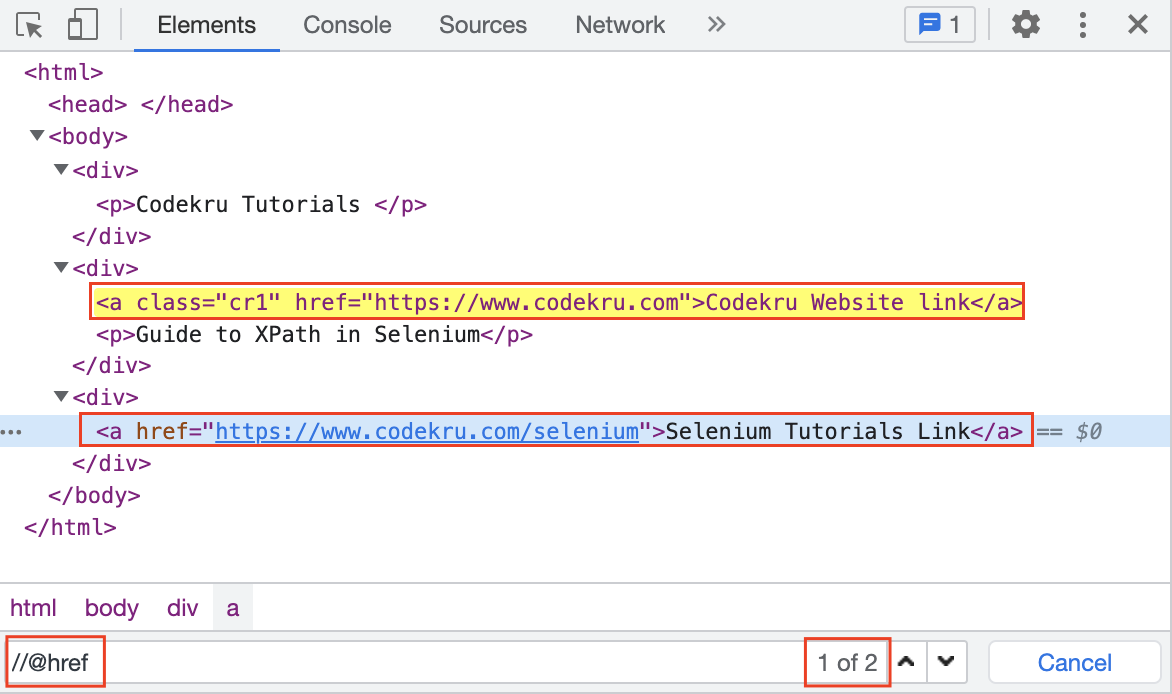
How to write the XPath to select a particular tag?
An HTML webpage is made up of tags like <html>, <head>, <div> and many more. We can follow the below syntax to select a particular tag.
//tag_name
Let’s say we want all elements representing the “div” tag.
The below XPath will select all elements representing the “div” tag.
//div
We can see that we got all 3 elements representing the tag.
How to write the XPath to select tag(s) containing a certain attribute?
The syntax below can be used to write XPath to select tag(s) containing a certain attribute.
//tag_name[@attribute_name]
If we want to get all “a” tags containing the “class” attribute, then below XPath can help us achieve that.
//a[@class]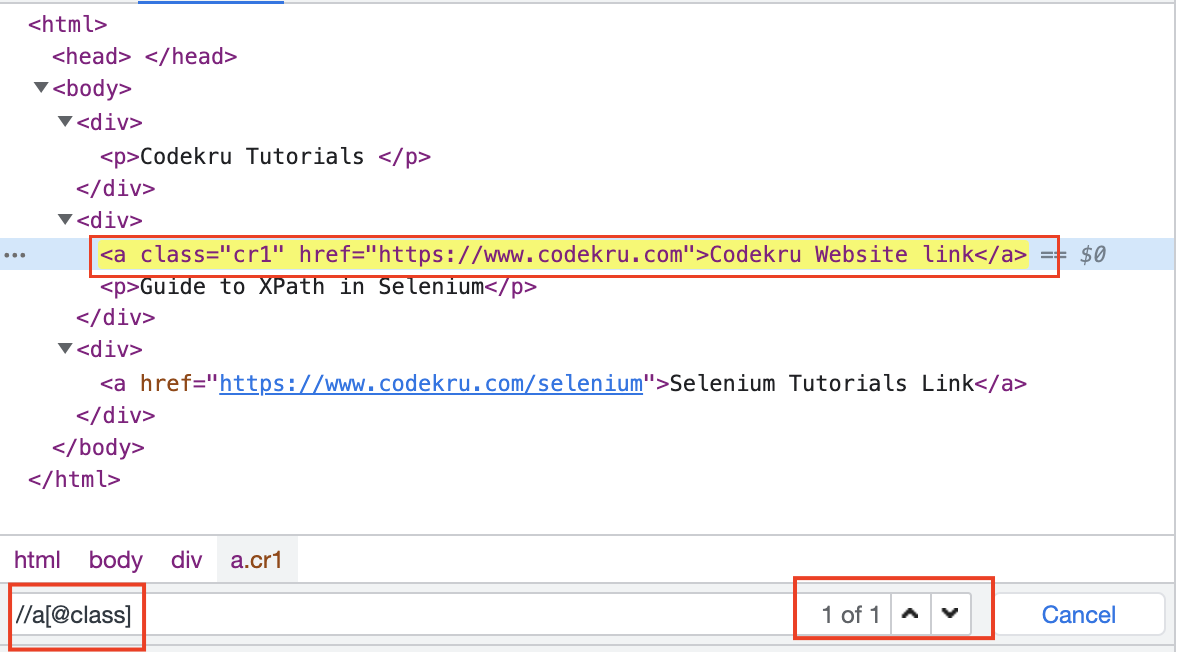
How to write the XPath to select tag(s) containing a certain attribute and a value?
We know that an attribute can have a value as well. Just like in our example, the “href” attribute’s value is “https://www.codekru.com” in <a class = "cr1" href = "https://www.codekru.com">Codekru Website link</a> code block.
There might be scenarios where we have to select an element based on the attribute and its value. The below XPath syntax can help us achieve it.
//tag_name[@attribute_name=attribute_value]
So, if we want to select element(s) with “a” tag having “href” attribute’s value equal to “https://www.codekru.com“, then below XPath can do the trick –
//a[@href = "https://www.codekru.com"]Above XPath is one of the most used while finding the element in a web application.

XPath Axes in Selenium
Until now, we have written an XPath using various expressions like single slash, double slash etc., but we can also use various XPath axes, which facilitates moving to sibling, ancestor, descendent, etc.
XPath axes is a very broad topic, and we will discuss it in a separate post for a better understanding of the concept.
Below is the list of XPath axes –
| XPath Axis | Description |
|---|---|
| ancestor | It specifies the ancestors of the current node |
| ancestor-or-self | It specifies the ancestors of the current node plus the current node itself |
| attribute | It specifies the attributes of the current node |
| child | It specifies the children of the current node |
| descendant | It specifies the descendants of the current node |
| descendant-or-self | It specifies the descendants of the current node plus the current node itself |
| following | It specifies all nodes that come after the current node. |
| following-sibling | It specifies the following siblings of the context node |
| namespace | It specifies the namespace of the current node. |
| parent | It specifies the parent of the current node |
| preceding | It specifies all nodes that come before the current node |
| self | It specifies the current node |
This is it. We hope that you have liked the article and got a better understanding of XPath in Selenium. If you have any doubts or concerns, please write to us in the comments or mail us at admin@codekru.com.